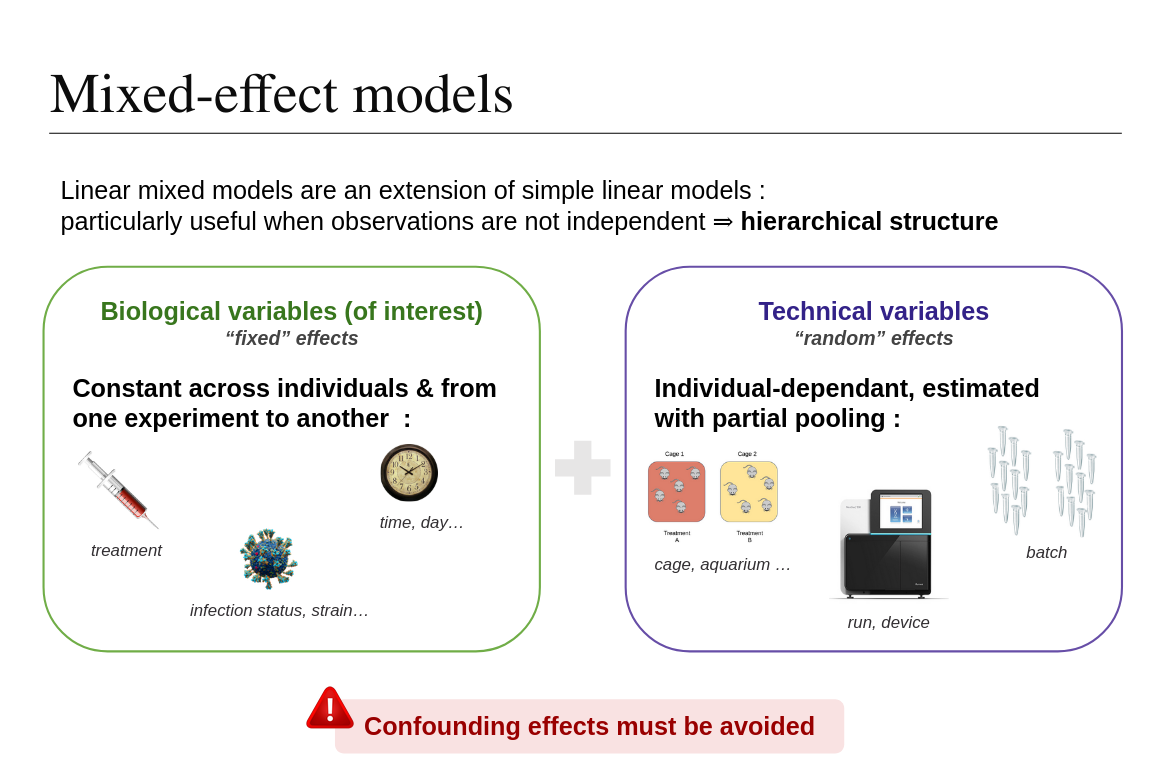
Welcome to Shade
SHADE is a Shiny application for providing support to researchers in design of experiments. It includes a tool to perform power analysis for usual test statistics, as well as a reporter tool to draft the ethics committee form for animal experimentation (CETEA), in a user-friendly interface. Initially created to design experiments using animals, SHADE might be used to design any experiments (cell culture ...).
Latest news
12/01/2026
SHADE gets a makover
SHADE version 4.0 offers a new user interface to facilitate navigation. You can now run a quick power analysis, or choose the guided section to get a detailed analysis according to your experimental design.
01/03/2023
New version of SHADE is online
User interface improved with an advanced tab for exploring parameters and language option in final report. Cage effect visualisation was also improved.
01/02/2021
Version 2.0 released
User interface was improved with validation buttons, tabs for exploring parameters. Bugs were fixed such as external data loading and numerical errors in power analysis.
01/01/2019
SHADE is online
Implementing power analysis for frequently used statistical tests, power graph and a report for CETEA form.
Team





Power Analysis
Test settings
Choose the appropriate statistical test for your data.
Hypothesis testing
Select a one-sided test if you already know in which way your effect is going to impact the measured variable (increase only or decrease only). If you have no prior knowledge on the effect you are trying to measure, a two-sided test is more suitable.
Experimental design
Nested or crossed design
Will the individuals of the same cage receive the same treatment (nested) of different treatments (crossed) ?
Add unwanted/external sources of variation
Unwanted sources of variation, such as technical factors, can impact the measures during the experiment. It is possible to take them into account during the power analysis, to have a more accurate estimation.
Power analysis parameters
Power Analysis
Guided analysis
General parameters
Select pathway
Compute power analysis
Download report
Experimental plan
Will the individuals of the same cage receive the same treatment ?
Unwanted effetcs
Unwanted sources of variation can impact the measures during the experiment. Those arre usually technical factors such as cage, repetition of the experiment, batches ... Taking them into account during the power analysis helps to have a more accurate estimation.
Are there any potential external factors in your design that you would like to include ?
Test settings
Pairing
Will all the measured be completely independent (unpaired) or are you are following the same individuals through time (paired) ?.
Hypothesis testing
Select a one-sided test if you already know in which way your effect is going to impact the measured variable (increase only or decrease only). If you have no prior knowledge on the effect you are trying to measure, a two-sided test is more suitable.
Guided analysis
General parameters
Select pathway
Compute power analysis
Download report
What variable do you want to estimate ?
Depending on the information and data at your disposition, choose the option that fits best :
Guided analysis
General parameters
Select pathway
Compute power analysis
Download report
Additional informations
In order to compute the power analysis, we need a few additional informations :
Preliminary data
double-click to edit cell
Estimated effect
Guided analysis
General parameters
Select pathway
Compute power analysis
Download report
Additional informations
In order to compute the power analysis, we need a few additional informations :
Preliminary data
Unwanted effects
Enter below the factors of your experiemnt that might introduce biases in your data. All selected unwanted effects will be regrouped to be modelized as "units". On average, a unit effect can represent between 10% and 20% of the total variability.
Power analysis parameters
Those values are conventionnaly set at 5% for false positive rate and 80% for power, feel free to modify them according to the specificities of your field :
Guided analysis
General parameters
Select pathway
Compute power analysis
Download report
Power analysis results
Type I error
Power
Effect size
n per group
Interpreting effect size
Analysis summary
Below is a summarised report you can copy/paste to the DAP document, to be reviewed by statisticians. You can also download a summary of the analysis to keep track of what parameters were used.
SHADE team
SHADE is an application developped by members of the Hub of Bioinformatics and Biostatistics of the Institut Pasteur.
Find more information about the Hub on the team webpage . Click here to contact the SHADE authors by email.
Contributors
Acknowledgements





Check out our other applications
We developped other Shiny apps to help you with experimental design. Do not hesitate to have a look !
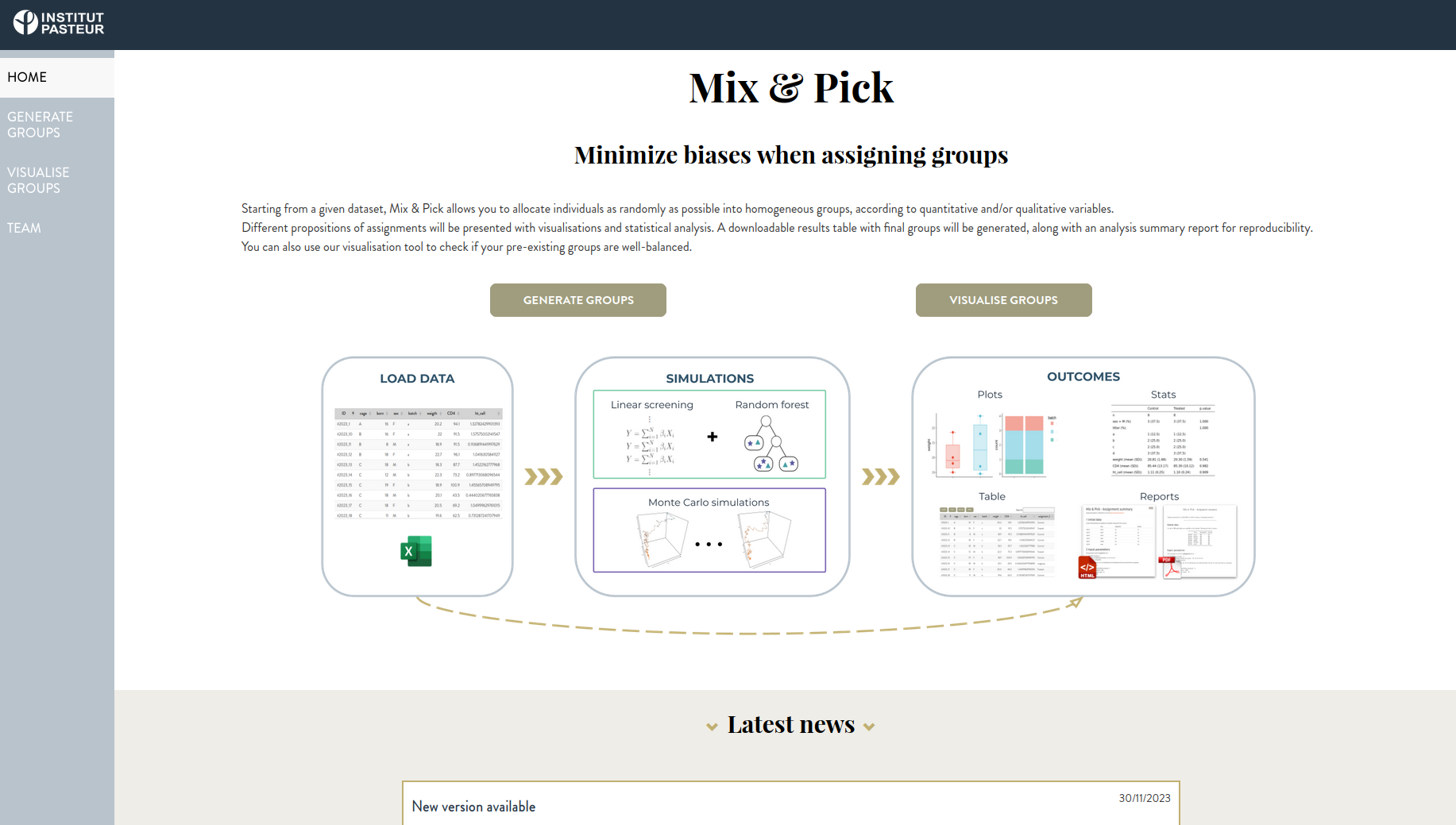
Mix&Pick : Radomization tool
Minimize biases when generating group assignments
User-friendly Mixed Models analysis
Perform statistical analysis with structured data